
공부 정리 블로그
[Chapter9]언어모델(4)-DNN 기반 언어모델 본문
DNN 기반으로 discrete 입력에 대해서, 대용량 자료에서 기존 n-gram보다 좋은 성능을 보이기 어려움
모든 input을 다 넣어서 계산해야하기 때문에
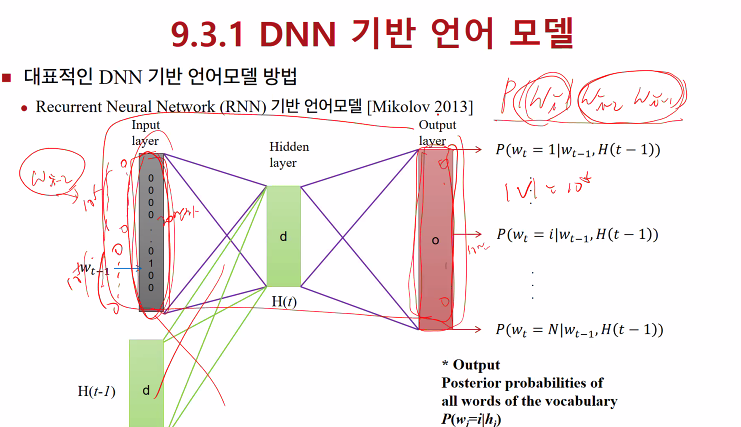

어쿠스틱 모델과 비교해보면 input, output 노드 수가 늘어남
모델의 추정해야하는 파라미터 수가 늘어났고 데이터도 많이 필요하게됨
input을 줄이는 연구가 필요하고 확률은 output layer의 모든 것을 구해서 softmax를 해야하는데..
output layer 를 계층적으로 만들어서 연산을 어떻게 줄일 수 있나(딥러닝 연구 초기 문제)
9.3.2. Word vector를 이용한 입력 차원 감소
computer가 보는 vector의 의미 : 양쪽이 같은 sequence 이면 유사한 의미를 갖는다고 봄
예:
- The cat is walking in the bedroom.
- The dog was running in a room.
ㅇ Distributional hypothesis
양 옆 단어가 같으면 유사한 단어가 될 것이라고 판단
ㅇ One-hot representatiaon 의 문제점
- 단어의 개수만큼의 차원이 필요
- 유사성이나 관계의 표현이 불가능 “tea”와 “coffee” 라는 두 단어에 대한 one-hot representation
의미없는 연산이 이루어지는 경우가 있음
Word2vec
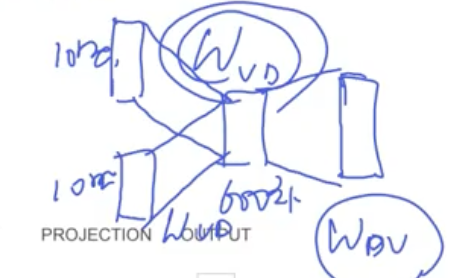

- Continuous Bag of Words (CBOW)
- Skip-gram
자꾸 word vector를 뽑으려는 이유는?
=> 의미를 벡터화 해서 벡터 연산을 이용해서 의미간의 차이를 정량적으로 뽑을 수 있음
ㅇ Measure Quality of the Word Vector


Athenes - Greece + Oslo = Norway
vector 연산으로 의미를 만들고
벡터 연산으로 의미-의미 차이를 정량적으로 나타내기 위해서
단어 간의 각도가 작을수록 유사한 각도로 나타낼 수 있음


ex) 조동사 can, 깡통 can
의미가 다른데, 양 옆에 오는 단어들이 달라져야하는데
하지만 CBOW, skip 은 똑같은 vector로 나오게 됨(문제)
그 이후, 어떤 방향으로 ?

9.3.6 Contextualized Representations
ELMo

양 옆 history를 참고해서 단어를 새로 뽑음
RNN 이용
양방향으로 보면서 word 임베딩을 뽑음
-> 조동사, 깡통 can 주위 단어가 달라지므로 단어 representation을 잘 뽑자(특화)
GPT

transformer 기반 학습
크롤링하고 앞 history -> 현재 단어
decoder 같이 생겼다 (transformer DECODER X, Attention 은 없음 )
GPT 앞에 history가 들어올 때 생성모델임 (마치 transformer decoder 처럼 생김)
BERT

transformer encoder 처럼 만들 모델
문장을 쭉 모으고 15%정도의 단어를 masking
나머지 15%의 단어를 복원해낼 수 있는가?
앞 뒤 context보고 니가 맞춰
이미지의 경우
차원이 정해져있음
음성자연어는 seq인데 길이가 들쭉날쭉함
~2011년 성과
- 단어의 의미를 가지는 index는 word embedding (~2011까지의 성과)
2013
- seq2seq 번역문제(2013)
길이가 다른 vector의 seq를 fix한 곳에 임베딩
-> 문장의 의미를 특정한 벡터로 바꿈
~2017
최대로 좋은 벡터를 뽑자

1. input vector가 너무 커서 줄이려는 연구 10만개 단어에 대한 확률을 다 얻어야 함
2. auto clustering 방법으로 class1000개에 대한 output layer를 계산
C100 = 0.3으로 나오면 해당 class에 나오는 단어의 확률의 합을 0.3으로 맞추면 됨
class 1000개 연산, 100개 단어 연산(10만개 연산이 아님 1000class*100개 단어로 연산하면 됨-> 1/100로 줄었음 속도 100배 빠르게 함)
'대학원 수업 > 음성인식' 카테고리의 다른 글
| [Chapter7] multi-Head Attention (1) | 2023.06.17 |
|---|---|
| [Chapter7] self-attention (0) | 2023.06.17 |
| [Chapter9]언어모델(2) - back-off, perplexity (1) | 2023.05.24 |
| [Chapter9]언어모델(1) - ~smoothing (0) | 2023.05.17 |
| 중간고사 (0) | 2023.04.19 |



