
공부 정리 블로그
[Chapter9]언어모델(1) - ~smoothing 본문
Table of contents
arg maxP(W|O) (사후 확률, classification) = arg maxP(O|W) 음향 모델 x P(W) 언어모델
1. n-gram 언어모델
2. 카테 고리 기반 언어 모델(추천하는 방법은 아님)
3. DNN 기반 언어 모델 (단어 vector에 의미부여 : back-off, skip gram)
9. 언어모델 - 개요
ㅇ 언어 모델(마이크에 무엇이 들어오든 신경 쓰지 않음, 사전 확률 P(W))
- 특정단어 열이 주어졌을 때 다음에 나올 단어들의 확률을 추정하는 모델
예) 내일오후3시에(□) 가자
(□): 학교, 강남, 서점, 공원, …
ㅇ T개의 단어로 구성된 문장 𝑊(𝑤0…𝑤𝑇)에 대해서 문장 생성확률 𝑃(𝑊)=𝑃(𝑤0…𝑤𝑇)을 계산
ㅇ 단어를 구분하는 단위 (동북아시아권 형태소 단위가 좋음)
- 형태소(morpheme): 의미를 가지는 언어단위 중 가장 작은 언어 단위이다. 그러므로 형태소는 더 쪼개면 전혀 의미가 없어지거나 또는 이전의 의미와 관련되는 의미가 없어지는 문법 단위이다.
예)내일 오후 세시에 학교 가자
내일/오후/세/시/에/학교/가/자
ㅇ 어절 : 어절은 띄어쓰기로 나누어지는 언어 단위이다. (유럽어권)
- 예제 : 내일/오후/세시에/학교/가자
어절은/한국어에서/문장을/…/단위이다.
길동이가/공부를/한다.
- 영어의 경우에는 단어의 단위가 어절임
Let’s/go/to/school/tomorrow/at/three/pm
ㅇ 음절

한글의 음절을 완성형으로 보면 '독', '녹' 두 개는 유사한 발음이지만 초성이 다른 유사한 음절이
2000개의 음절을 넣은 간단한 말뭉치를 만드는 걸로 끝나지 않는 이유는?
한 단어씩 한 단어씩 넣은 것을 (업데이트 필요)
언어모델 - 개요

어떤 발음을 발화했든지 상과없이 제일 첫 번째 단어는 마이크를 통해서 들어온 것은 <s>,
음성인식 결과를 만들어보면 어떤 문장으로 시작되는지 상관 없이 제일 첫 번째 단어는 sentence begin (마이크가 열리기 전에 나오는 단어(예외처리 해줘야하는 이유?))
언어 생성 확률 == 각 단어의 생성확률의 곱

ㅇ 언어모델(Cont.)
- 단어 별로 decomposition을 한 후, history(𝑤𝑘−1𝑤𝑘−2…𝑤0)로부터 다음 단어(𝑤𝑘)를 예측함
- T 개의 단어로 구성된 문장 𝑊(𝑤0…𝑤𝑇)에 대해서 문장 생성 확률은 아래와 같이 계산됨

- 단어별 생성 확률은 음성인식 decoding network의 각 단어의 end state에서 적용됨
index가 다르면 서로 다른 단어임
같냐/다르냐 만 알 수 있음(유사성 계산 불가능)
각 단어의 생성확률의 곱으로 표현됨, 하지만 단어의 수가 많아질 수록 한정적인 computation 계산을 하는 것은 불가능 해짐
<s>/내일/오후/세시에/학교/가자/</s>
P(<s>,내일,오후,세시에,학교,가자,</s>) = P(<s>)*P(내일|<s>)*P(오후|내일,<s>)*P(세시에|오후,내일,<s>)*P(학교|세시에,오후,내일,<s>) *P(가자|학교,세시에,오후,내일,<s>)*P(</s>|가자,학교,세시에,오후,내일,<s>)
ㅇ 각 단어들은 컴퓨터 내부에서 어휘에 대한 index로 표현
- 어휘(Vocabulary): 인식 가능한 단어들의 집합
- 예: 어휘의 크기가 10만이고, 단어들은 어절 단위로 구분 되었으며, 어휘 내 단어들을 가나다순으로 정렬 했을때, 단어들이 아래의 순서의 단어로 어휘 내 위치해 있다고 가정한다.
‘가자’:12,844번째단어
‘내일’:24,882번째단어
‘세시에’:35,493번째단어
‘오후’:69,864번째단어
‘학교’: 95,867번째단어
ㅇ ‘내일/오후/세시에/학교/가자’는아래와 같이 index의 열로 표현된다.
- 24,882/69,864/35,493/95,867/12,844
-> 숫자가 다르면 다른 단어로 간주하지만 대소 비교의 의미는 없어짐. 같냐 다르냐의 문제만 고려
9.1 n-gram 언어모델
computation 계산 문제를 해결하기 위한 history의 길이를 제한
ㅇ 문장이 길어짐에 따라 history 또한 길어짐
- 확률 계산이 computationally intractable하게 됨
- 계산이 가능하게 하기 위해서는 history의 길이를 줄여야 함
ㅇ 가정사항: 최근 n-1개의 단어로 구성 할 수 있는 모든 history는 같은 history로 다룸

ㅇ n-gram 모델
- Unigram : 현재 한 단어만 반영 / 돌잡이 아기 (엄마, 아빠,...)
- Bigram : 바로 앞 단어까지 반영/ (아빠 물!, 의도는 알 수 없음)
- Trigram : 바로 앞 두 단어까지 반영
ㅇ Estimating n-Grams From Counts

𝑓(𝑤_𝑖−2,𝑤_𝑖−1) : 조건부 == 2단어의 튜플의 개수
𝑓(𝑤_𝑖−2,𝑤_𝑖−1, ,𝑤_𝑖) : 세 단어의 튜플 카운트
ㅇ N-gram 언어 모델의 장점
- 통계적 모델로써 계산의 간편함
- 대용량 학습자료를 이용하여 쉽게 모델 생성이 가능함
ㅇ N-gram 언어 모델의 단점
- N의 제약으로 인하여 longer history에 대한 정보를 표현하지 못함
예) 말뭉치에 아래 세 문장이 있음
<s> I am egg </s>
<s> Joe I am </s>
<s> I do like green and egg </s>
ㅇ Bigram 언어 모델 생성확률
P(I am egg) = P(I | <s>)*P(am | I)*P(egg | am) = 2/3*2/3*1/2 = 2/9

- P( I | <s> ) = C(<s> I ) / C( <s> ) = 2 / 3
- P( am | I ) = C( I am ) / C( I ) = 2 / 3
- P( egg | am) = C( am egg ) / C( am ) = 1 / 2
(EM에 따라 만듦 -> test할 때, 학습자료 들어감 -> 다른 test 자료에 따른 정확도 반영 x )
(핵심)UnSeenBigram 을 어떻게 표현하느냐?
ㅇ n-gram 언어모델 ARPA format(N gram 저장 표준 포맷)


값들이 음수인 이유 : 확률은 본디 (0~1)인데, log 함수로 표현하면 logP<0
P(negative | comments, who)를 tri gram tuple의 확률을 log 로 표현
하지만, Tri-gram도 잘 안되는 이유?
ㅇ 메모리 문제
- 어휘의 크기가 10만(10^5)인 경우, tri-gram tuple은 세 단어의 index로 표현됨
- table 형태로 저장하기 위해서는 3차원 integer table이 있어야 함
- 이 경우 tri-gram tuple수는 105*3이며, 필요한 바이트수는 4 * 10^(5*3)B = 4 * 10^3 * 10^3 * 10^3 * 10^3 * 10^3B = 4,000TB (1TB 외장하드가 4천개가 필요 함) => tuple frequency table을 만들기 위해 추정 해야하는 parameter수가 많음
학습자료가 왜 부족한가? 어느 정도 부족한가?
ㅇ 학습 자료의 부족
- 예) 특정 방송국이 100년 간 방송한 자료가 있다고 하자. (계산의 편의 상)1년에 300일, 하루에 20시간을 방송하였다고 가정하면, 총 수집한 오디오의 양은 600,000시간 분량이다.
- 영미권 뉴스의 경우 100시간 당 100만 단어가 발화된다고 알려져 있다. 같은 기준을 적용하여, 100년간의 방송자료에 대해 transcription을 만들면 60억(6*10^9)단어= ( 600,000 시간* (100만 단어/ 100시간))가 존재함.
- Table의 셀개수가 10^15개임을 감안하면, tri-gram tuple의 수가 현저히 부족하다.
코퍼스를 아무리 많이 모으더라도, 실제 발화에서 나타나는 𝑓(𝑤𝑖−2,𝑤𝑖−1,𝑤𝑖), 𝑓(𝑤𝑖−2,𝑤𝑖−1)를 적절히 추정하지 못하는 경우가 발생하며, 최악의 경우는 0이 되는 경우임. 아무리 모델을 잘 만들어도 인식하지 못함
=>이후의 연구 철학 : 모은 corpus에서 나타나지 않은 튜플에 대해 어느 정도 count(확률)를 만들어 주는 것이 적절할까?
위 문제를 아래의 두 가지 방법으로 해결:
◼Discounting & Smoothing
- 0의 값을 가지는 𝑓𝑤𝑖−2,𝑤𝑖−1,𝑤𝑖에 대해 작은 값으로 flooring 시킴
◼Backing-off:
- trigram 모델로 언어 모델 생성확률 계산 시 𝑓(𝑤_(𝑖−2),𝑤_(𝑖−1),𝑤_𝑖)이 작아 적절한 확률 추정이 어려운 경우, 모델링 파워는 낮지만 적은 양의 코퍼스로 부터 적절한 확률 추정이 가능한 bigram,unigram 언어모델 확률로 대체하는 방법
9.1.1 Discounting & Smoothing

(10^5)^3개 튜플 하나하나의 등장 빈도를 센다
한 번 나온 튜플의 누적 카운트들, 두 번 나온 튜플의 누적 카운트들, ...
0이 왜 나오는가?
아무리 학습자료를 모아본 들, 학습자료가 부족하게 됨 -> 대부분이 0개를 가지게 됨
근데 왜 아무도 없어...?
0*(수 없이 많은 튜플) => 아무리 많아봐야 0이 됨(누적카운트 0) => 이 녀석이 문제를 일으킴
그래서 unseen tuple 에 확률을 부여하려하는데,
확률의 총 합은 1(확률분포)이므로, 새로운 확률을 만들어 줬다는 것은 다른 scene에서 확률을 떼어줌

1에는 d1만큼, 0에 1-d1만큼 떼어준다.
9.1.1.1 Laplace Smoothing (add1 smoothing)
단어 8개일 때, 이론상 쓸 수 있는 bigram 튜플 8^2 개
여기서 관찰할 수 있는 seenbigram-tuple은 10개, 하지만 나올 수 없는 튜플들도 있음


우리가 하고자하는 것 : 나머지 unseen은 어떻게 처리할 것인가?
<s> sell seel </s> = P(sell|<s>) x P(sell | sell) x P(</s> | sell) -> 최댓값의 확률을 갖는 값으로 나올 수 없음(절대)
음향 모델을 아무리 잘 만들어도 음향 모델과 언어모델 곱이 0이 됨
그래서, 8단어로 구성하는 모든 tuple이 관측되면 좋지만, 54개의 corpus에 대해서 아주 작은 확률들을 부여해주려 함
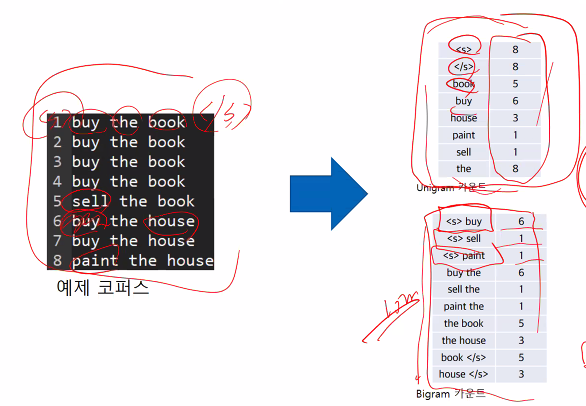

이해하고 구현하긴 쉬우나, (단점)상당 수는 절대 발화될 튜플이 아닌데, 1 부여하므로 아무런 수학적 근거가 없음 => 성능이 좋지 않음
smoothing 하는 이유 ! seen에 대한 확률을 낮춰주려고 함(seen에 대해서 unseen 에 확률을 떼어줌)




ㅇ Laplace Smoothing의 문제점
- 일반적으로 비관측 이벤트가 관측 가능한 이벤트보다 많음
- 비관측 이벤트에 대해 너무 많은 확률을 할당
- 다른 smoothing 방법에 비해 성능이 매우 떨어짐
9.1.1.2 Add-k smoothing
1을 더하는 대신 1보다 작은 수 k를 더함
Laplace smoothing 보다 성능은 좋지만 여전히 성능이 떨어짐
여전히 성능이 떨어짐 => k를 더하는 수학적 이유가 없음
9.1.1.3 Good turing smoothing
n번 관측된 이벤트에 대해 n+1번 관측된 이벤트의 횟수를 사용(n=0, 1, …)

Good turing estimate으로 count 재추정

Seen : count - / UnSeen : count +
ex)
bigram tuple에 대한 출현 횟수와 카운트

unigram tuple 개수 V = 14585
Seen bigrams (n1 +... nr) = 138741(한 번 나온 tuple)+25413(2번) +10531+…(n번) = 199252
N=615876 (전체 tuple 개수)

EM으로 세어보면 한 번도 안 나온 애들인데 0.00065를 모두 뿌려줌


가정 : 이상적인 값은 r보다 작아져야 함
현실 : corpus가 유한
'대학원 수업 > 음성인식' 카테고리의 다른 글
| [Chapter9]언어모델(4)-DNN 기반 언어모델 (0) | 2023.05.31 |
|---|---|
| [Chapter9]언어모델(2) - back-off, perplexity (0) | 2023.05.24 |
| 중간고사 (0) | 2023.04.19 |
| [음성인식2] - 입/출력 end 복잡도 분석 (0) | 2023.03.15 |
| [음성인식1] - 연구 동향 및 문제 정의 (0) | 2023.03.08 |


