
공부 정리 블로그
[Chapter7] multi-Head Attention 본문
같은 단어를 반복하고 있을 때, 비슷한 파형이 반복되면
전체 입력에 대한 Attention을 구할때, 음성하고 맞지 않다면
multi-Head Attention은 음성에 더욱 잘 맞음
vector를 끊어서, concatnation
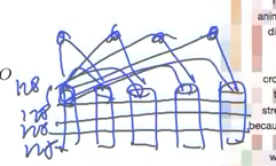
왜 잘 맞는가?
고주파, 저주파 대역에서의 특성이 다름, 대역별로 attention을 하게 만듦
seq2seq에서는 transformer가 제일 좋은 성능을 보이고 있음
의미를 vector화 한 것이 가장 큰 변화
단어는 Index인데, index가 다르면 의미가 다르다는 것까지만 알수 있음
1이라는 차이가 무엇을 뜻하는지에 대한 정보는 없음
문장을 Vector로 만드는 데 문제가 있음 -> 문장의 길이가 각각 다르기 때문,
RNN계열을 이용하여 vector를 뽑음
마지막 hidden layer의 출력값의 vector가 의미를 가지고 있다고 생각(embeding space)
문장, seq형태를 가지는(음성 파형) context vector를 특정 공간의 vector로 나타냈다.
문장과 단어간의 유사도를 나타낼 수 있음
vector에 해당하는 의미가 무엇인지 나타낼 수 있게 됨
end-to-end : 인간의 domain 지식 반영x, 데이터만 가지고 학습
'대학원 수업 > 음성인식' 카테고리의 다른 글
| [Chapter8] 음향모델(2) - Viterbi Algorithm (0) | 2023.06.17 |
|---|---|
| [Chapter8] 음향모델(1) - HMM (1) | 2023.06.17 |
| [Chapter7] self-attention (0) | 2023.06.17 |
| [Chapter9]언어모델(4)-DNN 기반 언어모델 (0) | 2023.05.31 |
| [Chapter9]언어모델(2) - back-off, perplexity (0) | 2023.05.24 |
'대학원 수업/음성인식' Related Articles
more



