6. Monte Carlo method(1/3) - prediction
내가 시행해보고 만번 굴려보고 만번 나눳다 expectation
V,Q 값을 계산으로 구할 순 없고 직접 해봐야함 - 추정 Monte Carlo !
추정(근사치)를 많이 할 수록 실제 값에 가까워짐

environmnet에 대한 V,Q값이 없는 상황에서 어떻게 가야하지? - model free
Random policy로 해본다. 동일한 policy를 유지하지만 stochastic environmnet이기 때문에 V(s)값이 다르게 나옴
그랬더니 V(a)가 각 4점, 3점, 2점 따라서 3.3점 나옴

1. [:t] -> [t:] (오타 정정)
한 episode 갈 때, 같은 곳을 여러번 거쳐 갔을 때 처리 방법
First-visit Monte Carlo
처음 값만 function 계산에 사용하겠다.
최상단 문구 한 줄 추가하면 First-visit Monte Carlo

Every-visit Monte Carlo
상관 없다. 언제든지 쓰겠다.
강화학습에서 design 해야할 3가지 요소
state : (내 카드 상태, 딜러 패, ACE 유무)
action : 못 먹어도 고 / 스돕
reward : win 1 / draw 0/ loss 1
Black jack
(15,9, True) (#my card sum, #dealer, #ACE유무)
(15,8, false) (9,6,8) 같은 액션을 취해야하는지, 다른 액션을 취하는지에 따라 state를 정의하는 것이 달라짐.
action을 어떻게 취하느냐가 state 동일 여부 결정
이럴때는 같은 걸로 취급하는 게 좋을까 다른 걸로 취급하는 게 좋을까?
같은 state로 보면 쌓이는 sample의 수가 많아짐 (Monte Carlo 관점)
state를 합치는 게 유리한 경우가 많음, 하지만 ACE 유무에 따라 state가 달라질 수 있음
prediction 직접 해보면서 V,Q값 계산
control 추정한 다음 policy를 계속 업데이트 해나가겠다.
prediction은 어떻게 하는가?
1. 아무 policy 정하기

2.
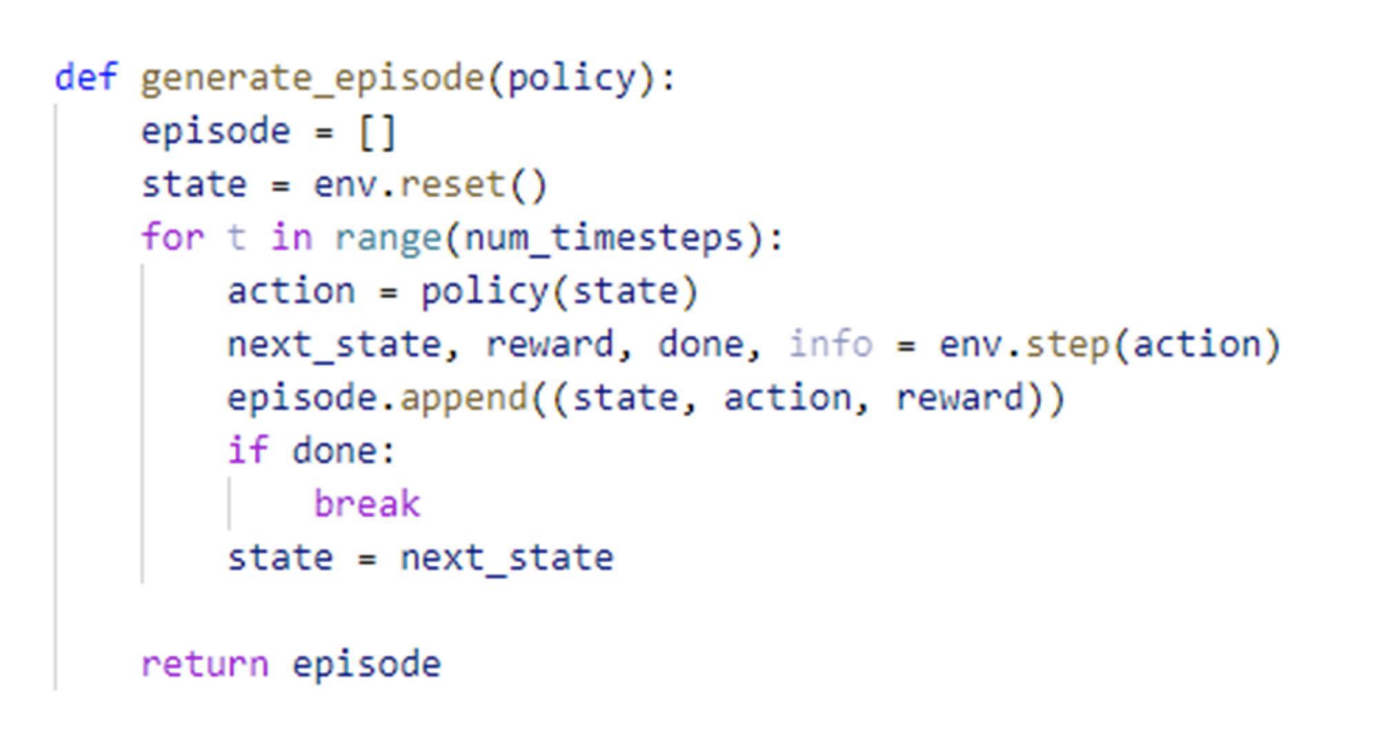
episoed = [] #state action reward 기록
action = policy(state) #action 취하기

num_iterations = 500,000 #500,000만번 계산해서 기대값 구함
R = (sum(rewards[t:])) #각 state에서의 return 값들을 다 저장
total_return = pd.DataFrame(total_return.items(), columns=['state', 'total_return']) #pandas로 저장