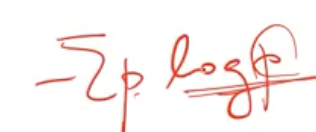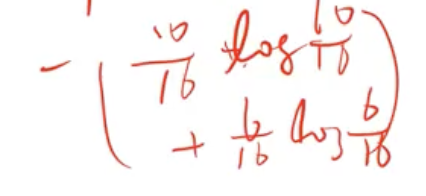[Chapter8] 음향모델(3) - DNN 기반
DNN을 이용한 음향모델
input, output layer 어떻게 결정했는지가 궁금
무작정 늘린다고 좋은 것은 아님 -> 추정해야할 parameter 수가 늘어남
vector의 길이만큼 cluster seq로 나타낼 수 있음
매 frame마다 8천개 정도의 state를 두고 모델링하면 됨
입력 vector는 13 vector, filter bank... 등등이 됨
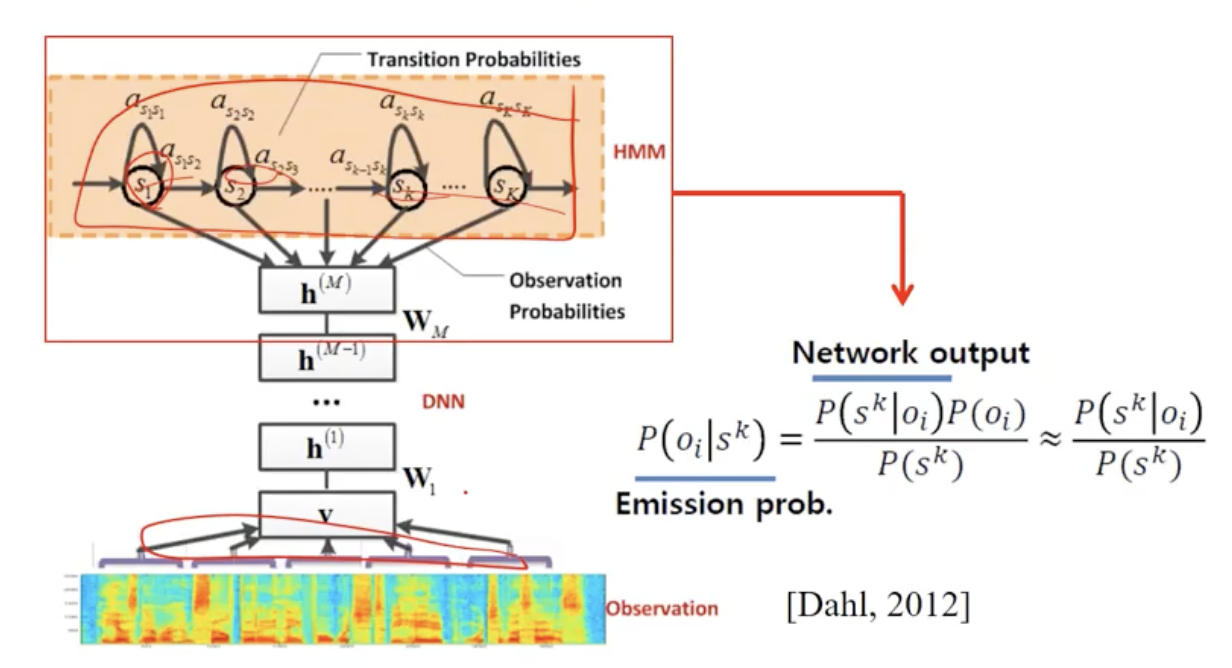
ㅇ DNN 기반음향모델시스템구성[Hinton 2010]
- 입력 layer unit의 개수: 600개(= 15frames X 40 filterbankoutputs)
- Hidden layer의 개수: 5~8 개(Layer 당unit의개수: 2,048 units)
- 출력 layer unit의 개수: 6,000 ~ 10,000개(Tiedstate 수)
8.3.1 개요 - 음소(Phoneme)
ㅇ 음소(Phoneme) : 다른 소리와 구별되어 언어 사용자가 인식하는 소리의 최소 단위
ㅇ 예:영어 단어 발음에 나타나는 발음 기호 하나하나
- phoneme[foʊni:m]
- CMU dictionary에서 사용하는 영어 phoneme set
ㅇ 음소열 변환 예제
- 문장 예: ‘교육에 관해서 이와 같은 의견을 말하는 것은…’ -> grapheme 음성 인식기 최종 출력
- 음소열 변환 결과: ㄱ ㅛ ㅇ ㅠ ㄱ ㅔ ㄱ ㅘ ㄴ ㅎ ㅐ ㅅ ㅓ # ㅇㅣㅇ ㅘ ㄱ ㅏ ㅊ ㅡ ㄴ ㅇ ㅢ ㄱ ㅕ ㄴ ㅡ ㄹ # ㅁ ㅏ ㄹ ㅎ ㅏ ㄴ ㅡ ㄴ ㄱ ㅓ ㅅ ㅡ ㄴ …
- 음소열 변환 결과에 따른 발음대로 작성한 문장: 교유게 관해서 이와 가튼 의겨늘 말하는 거슨… -> phoneme 말하는대로, 발음하는대로
한국어는 정형화된 언어로 20개 정도의 발음 규칙이 있음
8.3.1 개요 - Tri-phone
ㅇ 음성 인식에서는 일반적으로 앞뒤 context phoneme에 따라 음소를 다르게 모델링 함
ㅇ 이를 tri-phone이라함
- 왼쪽 context phoneme, 해당 phoneme, 오른쪽 context phoneme으로 모델링 함
- green( G R IY N )의 IY의 경우
앞 뒤에 올 수 있는 phomene 은 각각 40개
- 왼쪽 phonemeR, 해당 phoneme IY, 오른쪽 phoneme N 으로 모델링 함
ㅇ Tri-phone모델
- ‘좌측phoneme –해당phoneme + 우측phoneme’ 의 형태의 notation으로 표기
따라서 앞 장의 IY는 ‘R –IY + N’ 의 형태로 표기함
ㅇ Phoneme 하나당 모델링 되는 tri-phone의(이론상)개수?
- Phoneme이 40개인 경우, 좌측 context phoneme이 40개, 오른쪽 context phoneme이 40개가 위치 가능
- Phoneme 하나 당(40*40)=1600개의 모델이 가능
- 따라서 모든 phoneme은(40*40)*40=64000개의 모델이 가능
‘R –IY + N’은 64000개 모델중 몇번 째 tri-phone 모델 인가?
ㅇ Corpus에서 실제로 나타나는 tri-phone은 약 1만개 임
- ㄱ-ㄱ+ㄱ등은 불가능 함
- 이를 seen tri-phone이라 함
ㅇ Seen tri-phone 각각은 3 state-HMM으로 모델링 함
- 각각의 state에 대한 output probability가 적절히 추정되기 위해서는 학습 자료 중 해당state에 대응되는 vector가 일정량 이상이어야 함
- 상당 수의 state는 대응되는 vector의 수가 적음
- 유사한 state를 클러스터링하여 unique한 state의 수를 줄여주어야 함
- Decision-tree 기반의 state clustering 기법이 많이 사용됨


Decision tree 질문 내용들
- 오른쪽 context가 중설음인가요?
- 물체의 속성에 대해 질문 할 수 있음
Question set을 선택할 때 Entropy를 구함