[1장] 패턴 인식 소개
인식
사람에겐 쉽지만 기계에겐 어려움
컴퓨터라는 기계도 인식을 할 수 있게 만드는 것이 우리의 목표
왜 패턴인식인가?
뇌가 패턴을 어떻게 처리하는가를 이해하는 것이 필요
사람의 뇌 작동과 유사한 방식 -> 성능 낮음 -> 관심 식음 -> 다시 붐업 -> 좌절 -> 붐업~
물체의 중요한 특징을 어떻게 추출한 것인가 -> 분류/인식
패턴인식은 대부분 신경망을 이용하지만 최근에는 딥러닝으로 분류, 특징 추출을 자동화하고 있다
공학적 접근
영상 - 우편물 분류기, 필기 입력기, 동작인식 핸드폰(모션인식), 지문인식 마우스, 과속 단속기(땅에 매설된 센서 이용), 청소로봇
음성 텍스트 - 음성 인식기
패턴은 무질서의 반대이다.
무질서 하지 않은 모든 데이터 형태(홍채, 발바닥, 바코드 등)
흑백이 주로 나오는 이유는 계산을 용이하게 하기 위해
패턴인식의 가장 간단한 관점

특징 feature화 : 얼굴 크기 (x1), 코의 모양 (x2),눈썹의 짙은 정도 (x3), 눈의 크기 (x4)
특징이 어떻게 추출되는지. 분류 알고리즘에 따라 성능이 달라짐 다양한 알고리즘으로 특징을 추출할 수 있다.
분류 (인식) : qx1=작다, x2=뾰족하다, x3=짙다, x4=작다 라는 패턴이 들어왔을때, 이미 알고있는 지식에 비추어 아무개일 가능성이 높다라는 의사 결정 과정
대표적인 분류기 SVM, DT, KNN, Baysain 분류기, regression
부류 class(category)
데이터 베이스 수집
train / test/ validation(과적합 방지를 위해 사용)
특징 추출 방식


decision hyper plane 을 만들어가는 선형/비선형 분류기 차이
(a) 너무 간단한 모델
(b) linear < curve 유리
(c) overfiting
feature를 어떻게 뽑을 것인가


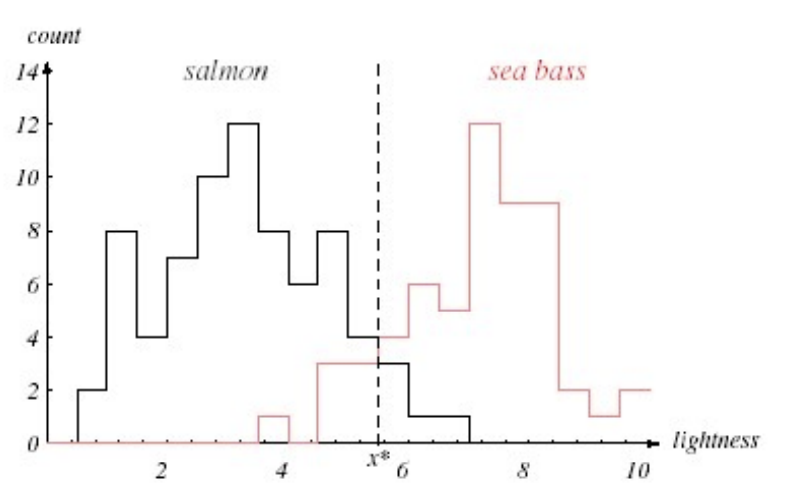
확률 밀도 함수 분류를 어떻게 수행할 수 있는지 보여줌
각각 길이, 밝기에 대해 분류함
feature가 달라지면 우도가 달라지게 된다 => prioir 함께 사용도 권장



(b) generalization이 좋지 않음 장점 없음... 굳이 있다면 training error가 적다(?ㅋㅋㅋ)
(c)처럼 단순한 모델을 사용해야 분류가 잘됨 curved가 linear보다 좋은 성능을 보인다
simple decision boundaries are preferred
성능 평가
어떤 class에서 오분류가 되는지 확인하고 시스템 성능을 개선할 수 있다
정확률(precision) : TP / (TP+FP) 정답이라 맞춘(예측) 것 중 실제정답
재현율(recall) : TP/(TP+FN) 전체 정답 중 맞춘 실제 정답 (정답 중 얼마나 맞췄는가)





성능지표 사용, positive를 얼마나 잘 찾아냈는가

일반화
패턴 인식기의 테스트 집합 (한번도 안본 샘플)에 대한 성능
과적합을 피해야 함
Occam의 칼날(Occam's razer) “쓸데 없이 복잡하게 만들지 말자” “단순한 것이 좋다”
모델 선택을 위해,
검증 집합 overfiting 판별
재 샘플링
- K겹 교차검증
(장)학습 data 양이 제한적일 때, 모든 data를 사용할 수 있다, (단) 시간이 많이 걸림
k 번의 paramenter 값이 다 다르기 때문에 평균 값을 모델에 사용
- 붓스트랩
random 하게 sampling한 여러 개 모델을 만들고 통합 후 최종 분류에 사용
subset sampling 중복을 허용하여 하나의 set 생성 -> 어러 버젼 생성 -> 각각 분류기 생성 -> 결과 합산
장
Classification (known categories) - 모양이 달라지면 feature가 달라질 수 있음
Clustering (learning categories) - 모양에 따라 모델을 만들고 clustering 한 다음 label 부여
지도학습, 비지도 학습
이미지 분류 : 객체검출(박스), segmentataion(픽셀)
사람은 쉽지만 컴퓨터에겐 종류나 이미지 각도, 딱딱(ligid), 말랑(non-ligind), 그리고 회전 이미지도 변화 가능성이 커 분류에 난이도가 있다
분류기 성능을 저하시키는 오류 원인들
Intra-class Variability : 동일한 class에서 다양한 모양으로 인한 문제점
Inter-class Similarity : 유사해보이는 sample의 문제점




현장 투입 (완전 자동 온라인 작동)
분할 (segmentation) 모듈 필요
다중 분류기 결합 채택 가능
후처리: /패(파)/?/인(임)/시(식)/ -> /패/턴/인/식/
분석적 풀이(closed form) vs 수치적 풀이(iteration 기반)