1. 강화학습의 개념
강화학습의 기초
(이론/수학적 Backgroun / 심층강화학습) -> 실제 코드로 구현하자
아기가 밥을 먹을 때, 숟가락으로 밥을 떠먹어라 알려주는 것 -> 강화학습 x
밥을 주고 숟가락을 주고 가만 있을 때, 숟가락을 사용 안하면 -10점, 숟가락을 사용하면 +10점
우연히 숟가락으로 밥을 먹을 때 박수 치는 게 강화학습, 방법을 알려주는 건 강화학습x
불필요한 초기 학습 과정이 심한 것이 강화학습의 단점
ex) 슈퍼마리오 -> 강화학습으로 학습할 때 초반에는 무조건 구멍으로 빠짐
벽돌깨기 등

RL이 무엇인가 (개념적인 얘기)
어떤 agent가 특정 환경에서 어떤 행동을 하면서 리워드를 받아서 점점 그 리워드가 높아지는 방향으로 행동을 바꾸도록 학습하는 것
ex) agent -> 바둑 player
직관과 느낌은 학습시키기 어려움
1. 현실세계에서 구덩이에 빠지면 다치거나 죽을 수 있단 걸 알고있다.
게임 캐릭터도 사람과 비슷하게 생겼기 때문에 떨어지면 죽을 것이라는 상식적인 가정이 있다.
2. 다른 플랫폼 게임, 비디오나 만화를 봤을 때, 떨어지면 죽을 것이란 걸 가정할 수 있다.
=> 사람은 다른 곳에서 경험한 지식을 다른 task에서 학습한 것을 다른 곳에 접목 transfer learning
인간 세계에의 경험을 게임에 적응
*General AI
로봇을 데리고 살면서 키우면서 나와 친해지고 나에 대해서 알게되면서 여러가지 task를 설정
지금은 실현 불가
마리오와 똑같이 생긴 platform 게임 10개 중 1개 수행 후 10번째게임 실행시 뛰어넘는 게 잘 안됨
다른데서 배운 학습적인 지식을 접목하는 것은 힘들다
사람과 AI의 가장 큰 차이 (교훈은 추상적)
추상적인 개념을 전혀 상관없는 다른 task에 응용하는 것을 머신이 하도록
*비지도 학습 - 정답은 없고 많은 사진을 레이블로 분류하고 비슷한지 안 비슷한지 분류
*지도 학습 - 말 고양이 사진을 주고(정답) 예측
*강화 학습 - interaction 하면서 분류
강화학습으로 다 되냐? => 어렵다
강화 학습으로 해결하기 쉬운 문제 => 반복적인 연습이 가능한 문제
- 바둑 => 왜 쉬운가? deterministic environment 바람이 불어서 바둑돌이 흔들리고 그런 환경은 없다
상대방(환경)이 놓으면 어떤 상태가 되고 이것을 감안해서 최적의 결정을 한다.
- 공장 로봇
- 게임
강화 학습으로 해결하기 어려운 문제
- 주식 예측 => (action - buy/sell) 어떤 종목의 주식을 사고 팔 것인지를 학습 학습데이터에선 완벽 / 하지만 미래가 중요하다. 똑같은 환경이 아니고 변동성이 크다
- 로또 예측 불가 => 과거와 상관 없이 pure random 이기 때문에

(episode 1)
어떻게 강화학습을 통해서 갈 수 있도록 할 것이냐? (기초적인 문제)
일단 해봐야해 해보기 전엔 알 수 없다.
처음에 할 수 있는 게 random action 밖에 없다.
terminal state -> state 중에 도착하면 끝나는 state (깃발, 죽거나)
어떻게 되던가 terminal state 가면 한 episode가 끝남

목표는 랜덤이 아닌 학습한 대로 움직여주길 원함
그걸 위해선 reward를 주는 방법이 있다 (다양함)
*reward를 어디에 주느냐가 중요
specific action on a specific state에 준다. 다시말해 (state, action)pair에 준다
=>A에 있을 때, 오른쪽으로 갈 것이냐 밑으로 갈 것이냐 그때 그때 리워드 다름
B에 있을 때, 오른쪽으로 갈 것이냐 밑으로 갈 것이냐에 따른 리워드도 다름
어떤 state에서 어떤 action을 취하냐에 reward를 주는 것
A에서 빗금으로 가면 -1, 빗금이 아닌 곳으로 가면 +1

random을 계속 반복
reward 준것을 table에 기록해서 reward가 커지는 방향으로 이동

A state에서 오른쪽 보다 아래가 좋은 거구나 라고 학습하게 됨
개념적으론 이렇지만 실제는 복잡
랜덤으로 갔는데 결국 잘 가게 됨 => 점수가 높네 ! => 이렇게 가고자 하는 경향성이 생긴다 => 행동이 강화된다 => 강화학습
내가 어떤 행동을 했을 reward에 따라 판단한다.
어떻게 저장해서 어떻게 할 것인가?

좋은 쪽으로만 가면 좋잖아요? => 꼭 그렇지는 않음
지금 당장 오른쪽으로 가는 게 좋아보여도 뒤에는 안 좋은 결과가 있을 수도 있음
=> 나한테 당장 주어지는 reward가 최선이 아닐 수도 있다. 결과적으로는 전체 episode로 판단이 필요
강화학습의 과정

1. agent가 action을 취한다
2. action을 취하면서 agent는 다른 state로 이동 (정지, 이동)
3. agent는 reward를 받는다
4. reward를 이용해서 agent의 action이 좋은지 나쁜지 판단
5. good, bad action good action 쪽으로 취하려는 경향을 보인다.
한 번 good이라고 옮겨가면 잘못된 판단을 할 수도 있다. => 조금씩 good으로 이동
RL의 5대 용어
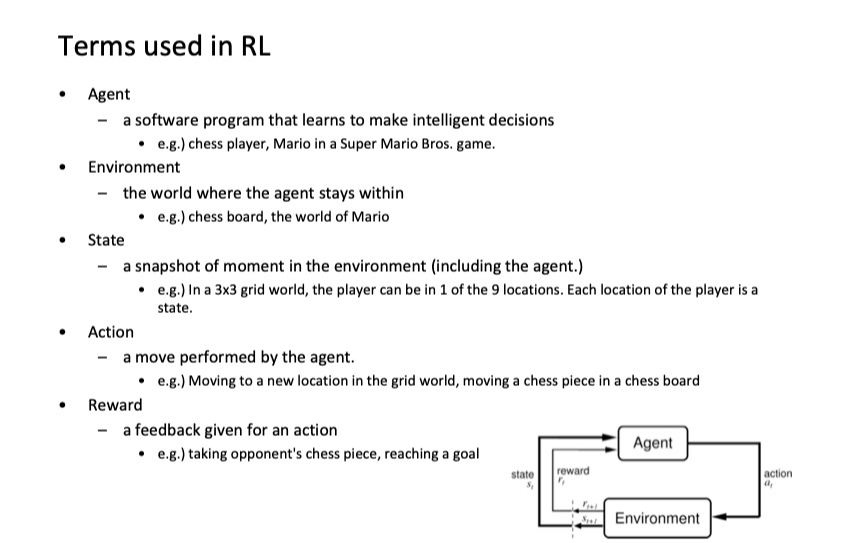
주어진 것 action, environment(만들기 보단 모델링)
ex) 5g 통신에서 주파수 자원 매니지먼트 주파수를 누구한테 배정해줘서
리소스 할당을 어떻게 하는 것이 가장 많은 서비스를 가장 많은 사람한테 좋은 화질로 이용할 수 있게 할 것인가
환경 정의 어떤 환경에서 몇명의 유저들이 어떤 주파수로 이용할 것인가
에이전스 기지국 어떤식으로 강화학습해서 누구한테 주파수를 얼마나 할당하는 게 가장 최적인지
내가 가지고 있는 문제에서 파생된 모델링된 환경과 학습의 주체
ex) 체스보드- 환경 / 플레이어 - 에이전트
만들어 내야하는 것 (Design 대상) 강화학습의 전체
1. state
정의할 때 중요한 것 state 마다 action 이 다르다면 다른 state로 가정해야한다.
ex) 바둑 - 흰 검돌이 놓인 상태
벽돌 게임 - 픽셀 그대로 / snapshot 4개를 이어 붙여서 진행 경로 상태 확인 등(위로 향하는지, 아래로 향하는지)
state를 설정하는 방법은 무궁무진
2. action design
바둑 - 어디다 두냐 / 자율주행 - 브레이크 밟아라 엑셀 밟아라
3. reward(중요!)
reward를 줄 때 agent가 내 목적에 맞게 움직이도록 설정
신의 한수 500, 우승 50 => 최적화된 값 != 목적

강화학습의 background - MDP
framework for solving optimization problems
어떤 최적화 문제를 풀기위한 framework
Markov property - future depends only on the present and not on the past
오늘 날씨는 내일 날씨에 영향을 미침 (ㅇ) / 과거는 상관 없고 지금 현재 나의 상태가 미래 나의 상태에 관여하는 것
memoryless property 과거를 기억할 필요 없이 현재만 기억한다.

오늘이 cloudy 면 내일 날씨를 결정하는 것에 각각 확률이 있음 / system 동작
action / reward 없음
Markov Reward Process(MRP)

Markov Chain = states + transition probability
Markov Reward Process =sates + P(s'|s) 지금이 s 일때 다음이 s'일 확률 + reward (reward f(x) = R(s))
Markov Decision Process(MDP)

MDP가 메인 !
MDP = MRP + action
action 이 없으면 운명에 따라서 밖에 못함 action을 취하기 위해서 만듦
Transition probability => state + action -> s'일 확률 (a+ 오른쪽 -> b)일 확률
Reward action => 현재 state / action / 다음 state ex)( a+ 오른쪽 -> b) reward
reward function 을 명확히 이해해야한다.