
공부 정리 블로그
[Chapter10] WFST(2) 본문
Finite State Acceptor (FSA)

input a, b인 경우만 accept, 그 외엔 accept X
state 개수 유한함
Less trivial FSA
accept : aa, aab, aaab, aa*b
Epsilon symbol (ε)
The symbol εmeans no symbol is there(non-deterministic)
This example represents the set of strings {a, aa, aaa, . . .}
If εwere treated as a normal symbol, this would be {a, aε a, aε aε a, …}
Weighted finite state acceptor
얼마나 잘 accept하는지를 weight를 통해서 나타냄
Weighted finite state transducer(통역사)
한국어 -> 프랑스 에 대응되는 symbol이 있음
- Input symbol: a
- Output symbol: x
- Weight (a→x): 1
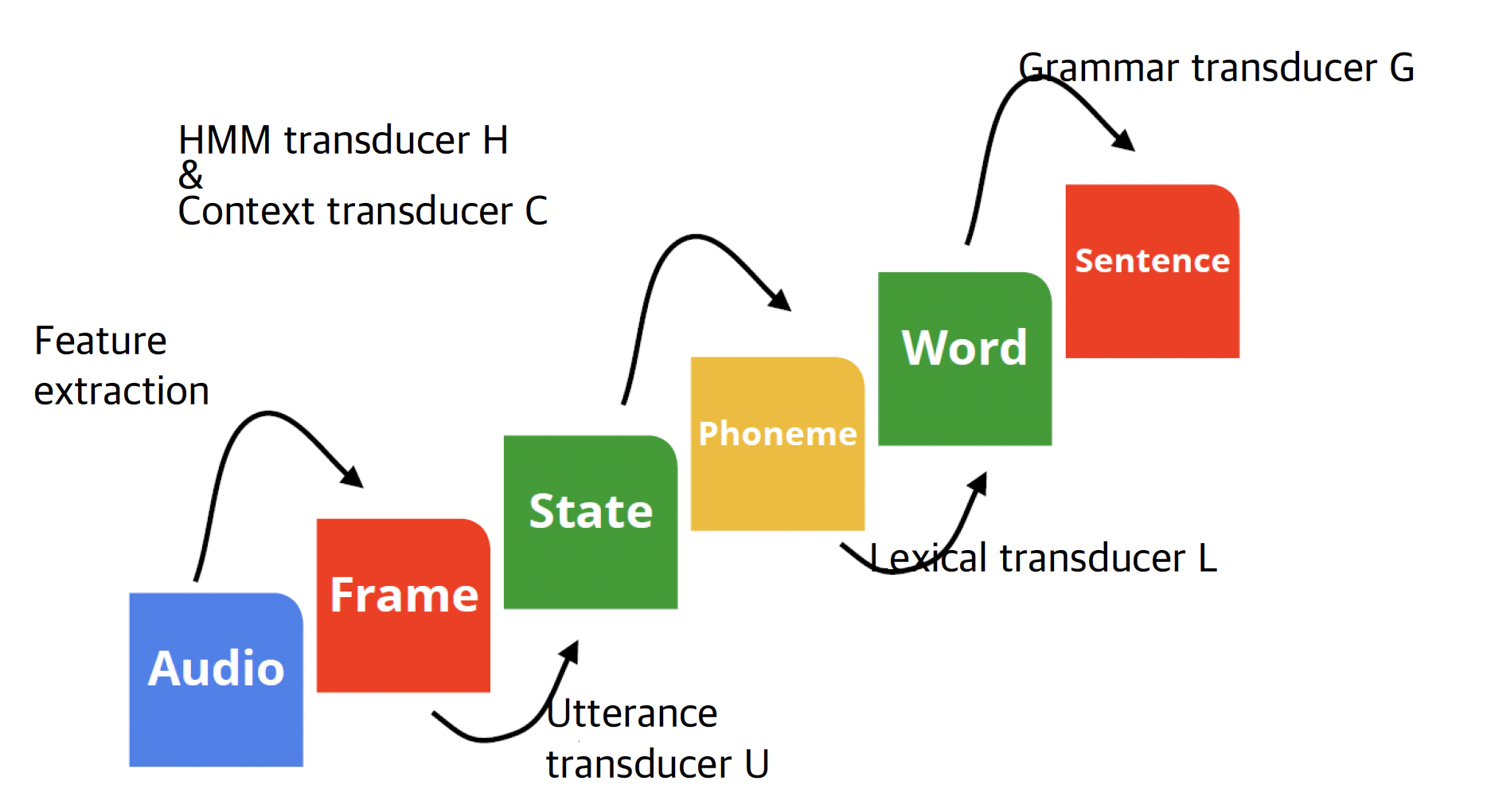
10.2.2 WFST 기반 디코딩 구성 요소
최종 목적
𝐻𝐶𝐿𝐺=𝑎𝑠𝑙(min(𝑟𝑑𝑠(det(𝐻_𝑎∘min(det(𝐶∘min(det(𝐿∘𝐺)))))))
10.2.2.1 Grammar transducer(G)
Grammar transducer G
ㅇ Grammar transducer 로써, 언어모델 arpa 파일로부터생성됨
ㅇ G에 대한 model topology
2- gram tuple 25개 중 6개만 나타 남
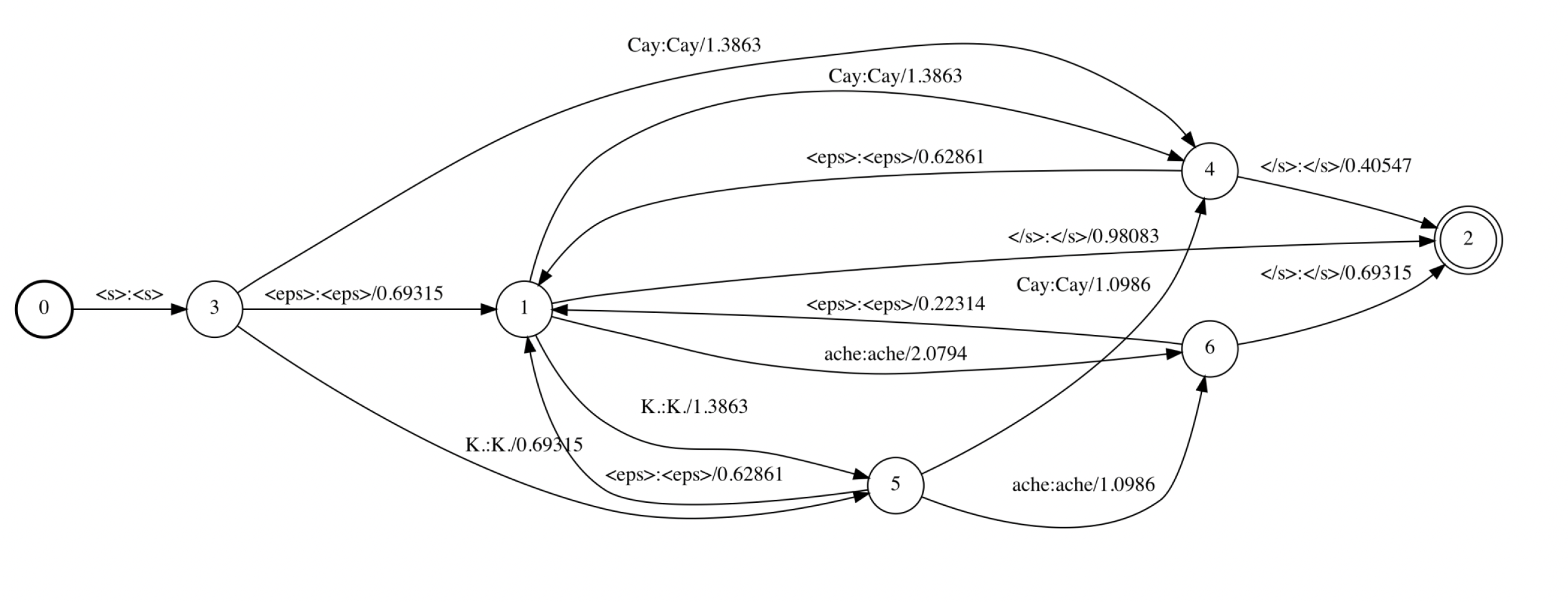
(<s> k. k. </s>) : 이런 출력은 seen bigram에서 나올 수 없음
5개 단어로 만든 G transducer도 한 페이지가 꽉 참
예제)
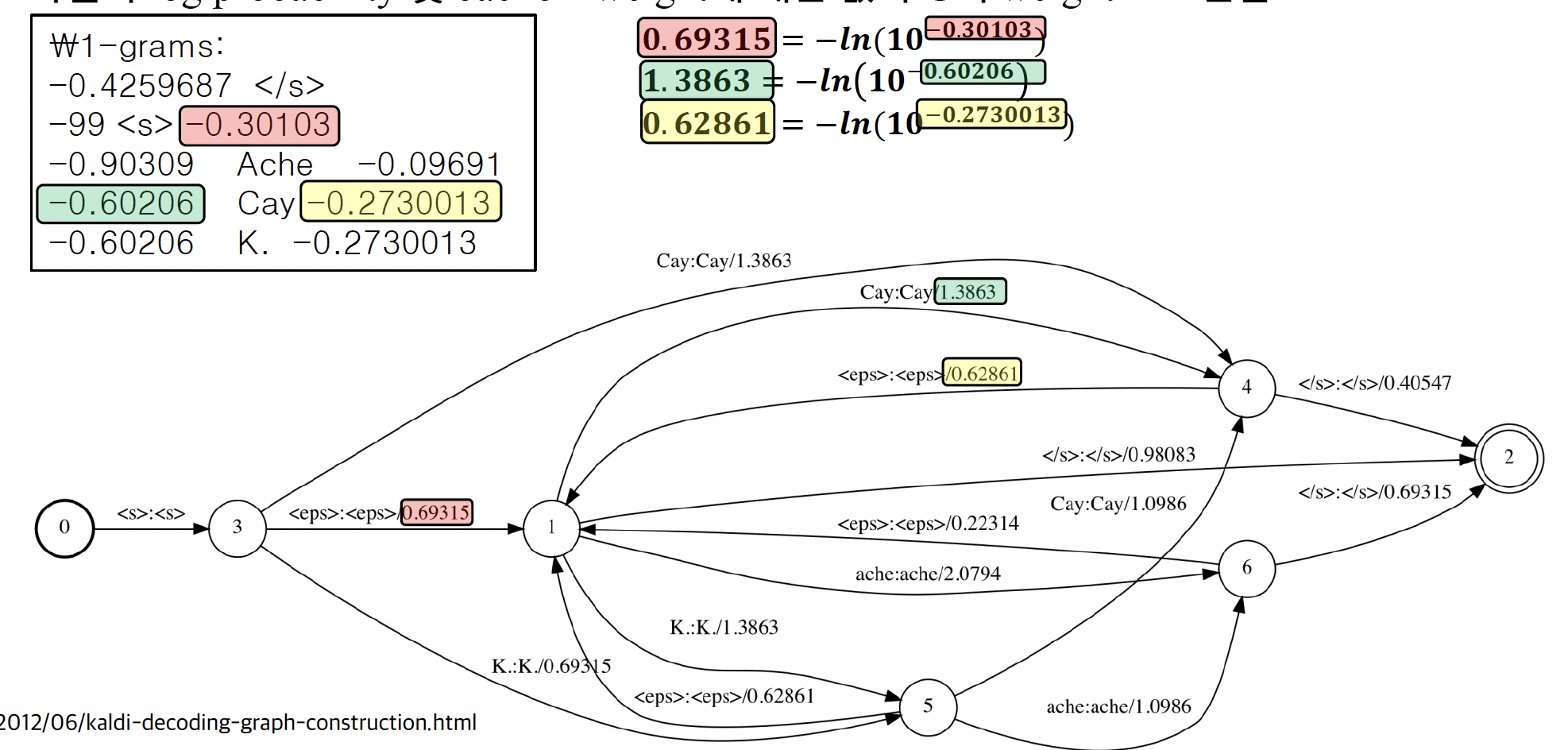
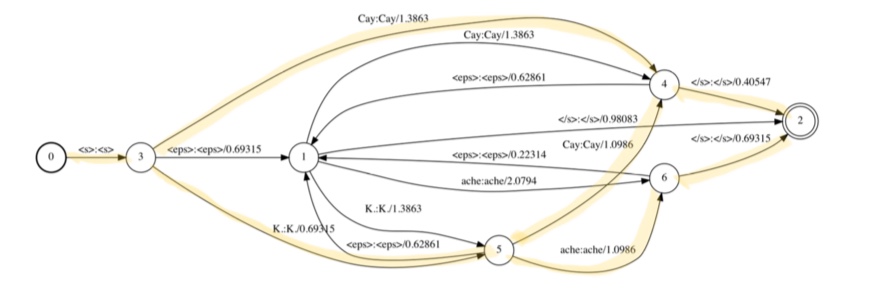
1-> 4 :
4 ->1 : history를 보고 alpha를 줘서 K.를 봄.
K.를 보고 들어가는 곳은 5이므로(history가 K.), -ln(10^(-0.273) 오른쪽에 있는 것
1->5 : -ln(10^(-0.602)
(주의)
2->1 : </s> 가 history가 되어버릴 수 없음
3-1
0 -1 - 5 -1- 2 root 개척 -> 인식 가능해짐
tri-gram 을 만드려면
V^2만큼의 gransducer가 만들어짐
cf. bigram은 단어의 개수만큼
Uni gram G transducer 사용
Uni-gram 언어 모델을 이용한 WFST G 생성 방법

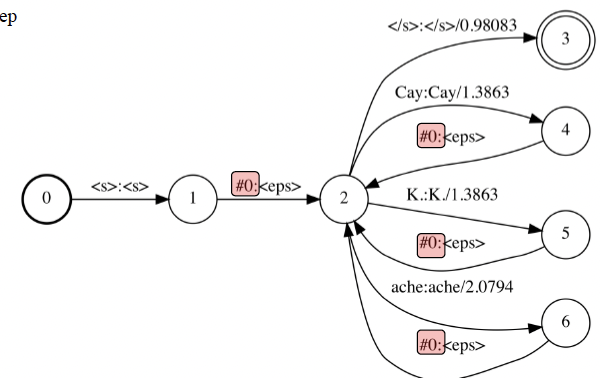
단어의 seq를 출력하면서 얼마나 잘 accept되는지 weight로 판단
입력 : vector의 seqence 들어옴
#0 : nput, output seq symbol 사이 속도 차이를 accept할 수 있게 만든 special symbol 넘어오지 않으면 홀딩 시켜줌 (2,3,4,5,6 holding)
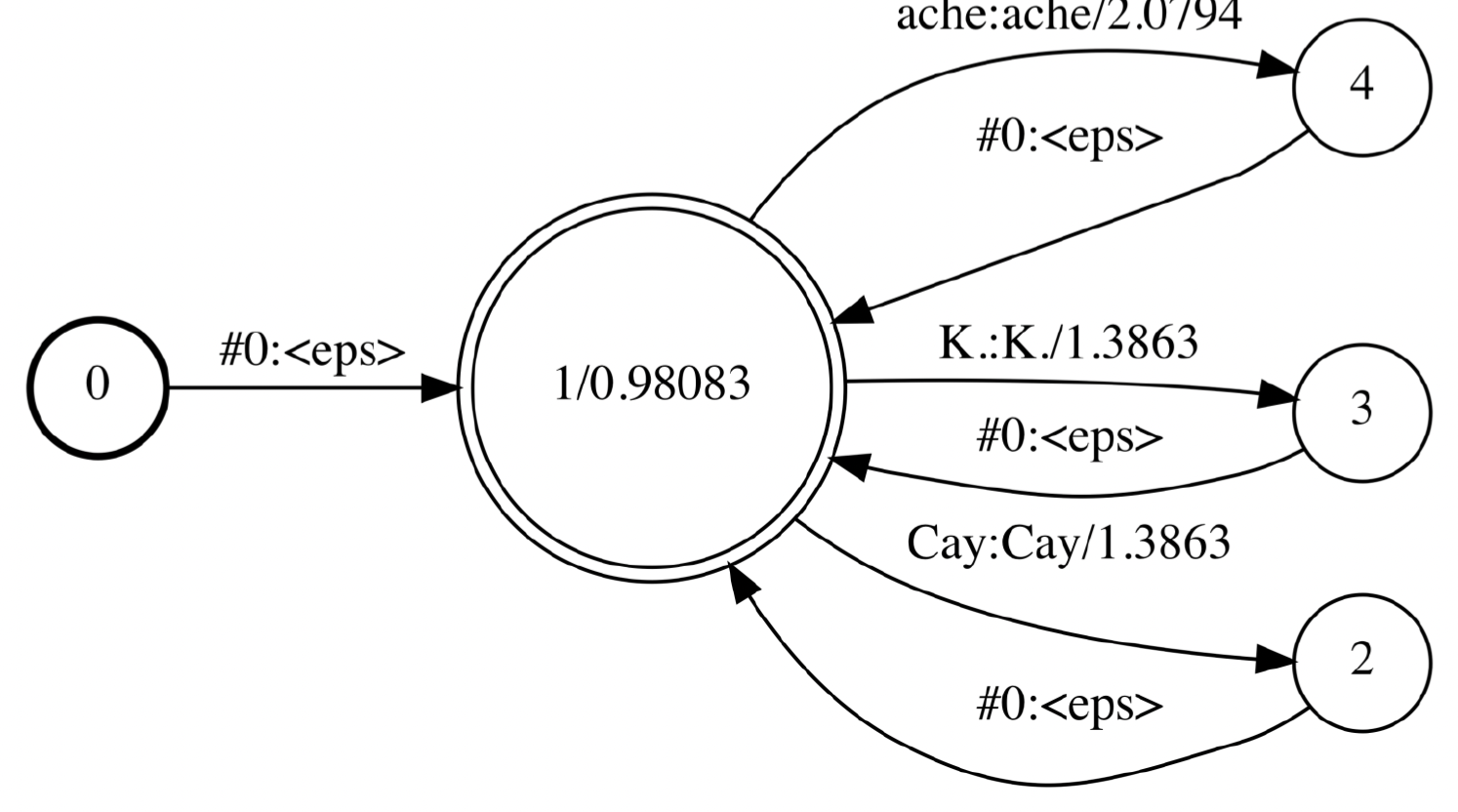
Step 1: ARPA 파일로부터raw WFST 생성
Step 2: Input이 epsilon인 경우, 이를 disambiguation symbol #0로 변환(#0 input, output seq symbol 사이 속도 차이를 accept할 수 있게 만듦)
Step 3: Start symbol (<s>) 및 end symbol (</s>)을 epsilon으로 변환
Step 4: Input과 output의 symbol이 모두 epsilon인 edge를 제거
ㅇ Pronunciation lexicon L
발음사전으로부터 WFST L 생성
input: monophoneme(Context-independent phon)
ouput : 단어

단어 사이 silence 를 허용하지 않다면 ccccaaaaayyyyy 이렇게 입력 해야함

10.2.2.3 Context-dependency transducer(C)
연이어 있는 a-b-c 중 b 가 center phoneme 이 됨

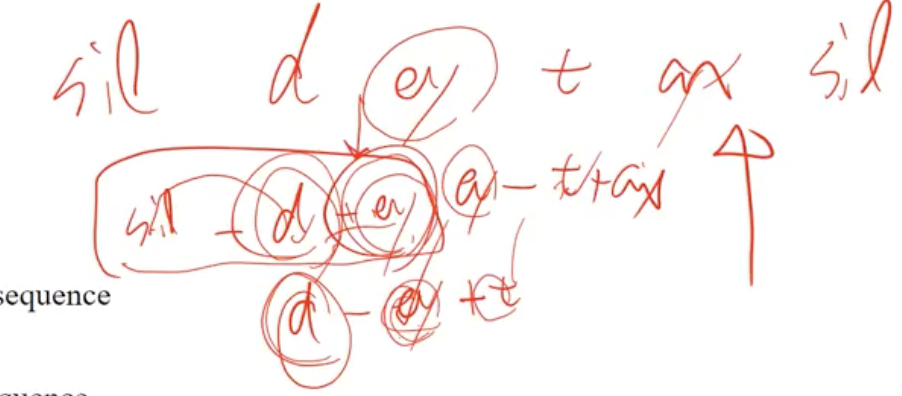
새로운 monophone으로 등장하면 오른쪽 context가 center-phone으로 됨 (한 칸 씩 밀림)
10.2.2.4 HMM topology transducer (H)
HMM 구조를WFST로표현
Maps states to phonemes
H에대한model topology
ㅇInput
- HMM state sequence
ㅇ Output
- Context-dependent phone (Tri-phone) sequence
ㅇ Weight
- HMM state transition probability
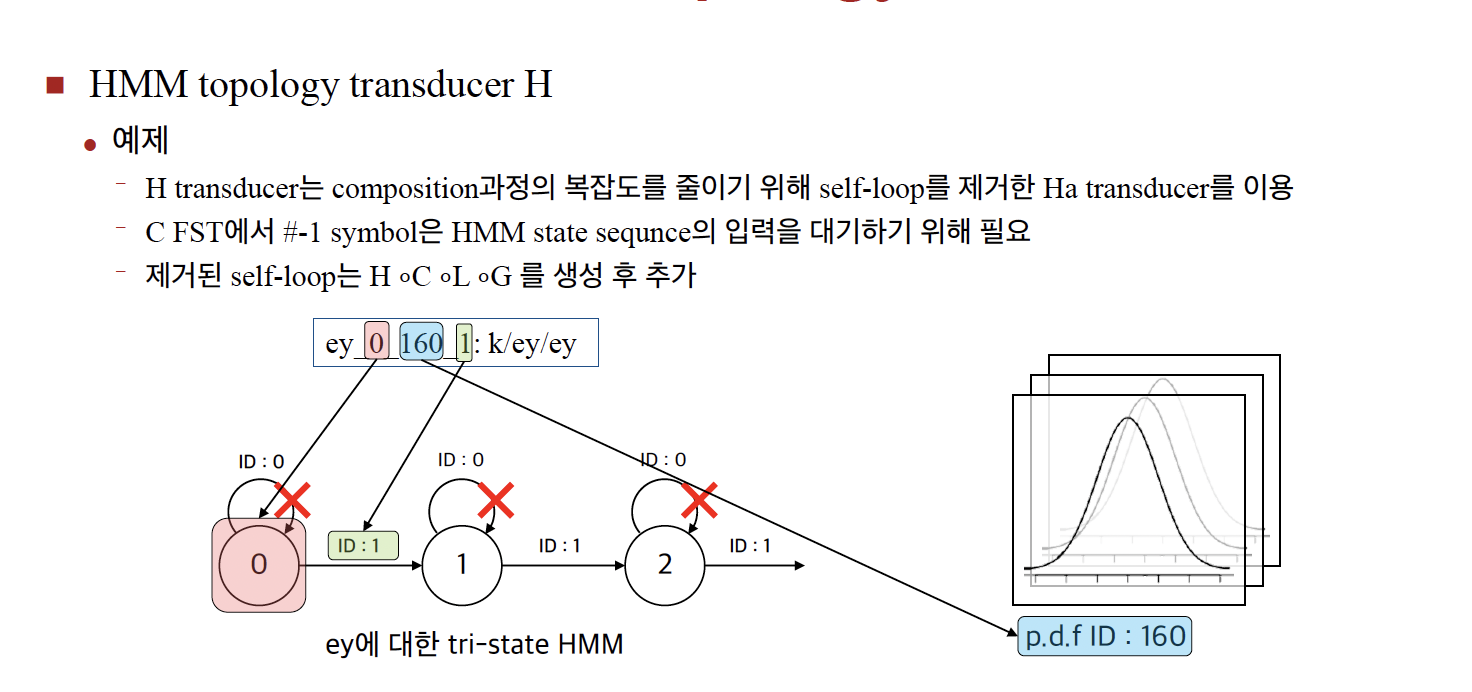
state seq -> tri-phone seq
하나의 seen tri-phone
전체에서 몇 번째를 클러스터를 모델링하고,
연두색 부분은 seen tri-phone 개수 만큼 있음
하늘색 - silence 모델링(ergodic 모델링)
10.2.2.5 Utterance transducer(U)
HCLG 마이크 입력 없이 만들 수 있음
Let S = U ◦HCLG 미리 만들어 놓은 것과 결합
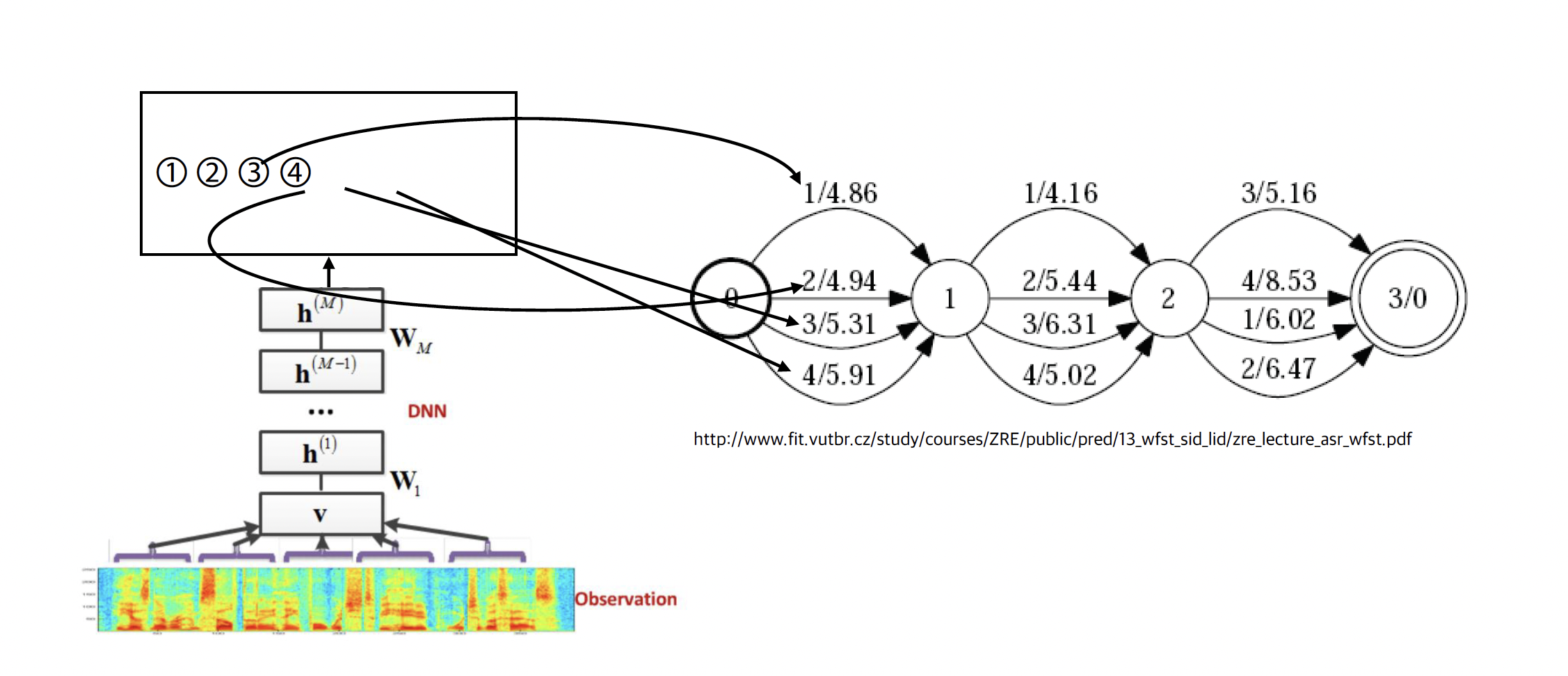

softmax 취해서 -ln를 아크마다 구해줌
마이크를 통해 소리가 들어오지 않으면 만들 수 없음
10.2.2.6 WFST 기반 디코딩 구성 요소–정리
d -ey + ey 를 매칭 시킬때,

이외에서는 가능하지 않음
미리 만들어 놓고 final 까지 도달 못하면 죽음
통과되면 monophone seq됨
음성인식에서 나오는 등장인물 tnasducer 5개,
G L C U
'대학원 수업 > 음성인식' 카테고리의 다른 글
| [Chapter9] 언어모델(3)- 카테고리 기반 언어모델 (0) | 2023.06.17 |
|---|---|
| [Chapter8] 음향모델(3) - DNN 기반 (0) | 2023.06.17 |
| [Chapter8] 음향모델(2) - Viterbi Algorithm (0) | 2023.06.17 |
| [Chapter8] 음향모델(1) - HMM (1) | 2023.06.17 |
| [Chapter7] multi-Head Attention (1) | 2023.06.17 |



