
공부 정리 블로그
Tempora Differnence Learning(1/2) 본문
지금까지의 이야기
Dynaminc Programing : model based
Monte-Carlo 여러번 시도해서 평균내기
return까지 기다리기 싫음
TD는
Bootstraping imm, 다음 가치를 통해 계산하겠다
속도가 빠르다


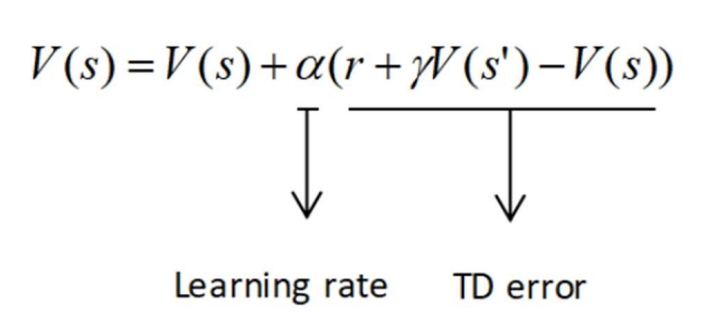
TD error : r+rV(s') 추구하는 값 - 현재 값


바보가 바보 따라가는 느낌이긴 한데...
하지만 결국은 제대로된 실제값으로 갈 것이다.
model based vs TD
model based 와의 차이는 trasition prob가 나오기 때문에 계산이됨
TD의 경우, ep를 전체를 가보지 않는 이상 최적의 policy로 가는지 모름
한 스텝을 갈 때마다 V값 업데이트
predition policy는 정해져있음 이것을 가지고 V,Q값 state , state action pair를 구하는 것
control은 그걸 토대로 policy를 바꾸는 것
prediction
episode를 많이 돌릴 때, 주어진 policy에 대해 돌릴 때마다 각 step을 갈때 모든 ep에 대해서 가기 전 state의 value를 update시켜줌
그러다 보면 V값이 어디로 결론남 이것이 우리가 추정한 가치라고 여김