
공부 정리 블로그
0122 오늘 한 일(정규화, 메모리 체크, groupby) 본문
1. 정규화하기
자꾸 코사인 유사도가 너무 낙게 나와서 결과가 제대로 도출된 것인지 판단이 전혀 되지 않았다.

정규화하니 0~1사이 값으로 유효한 결과가 나왔다.
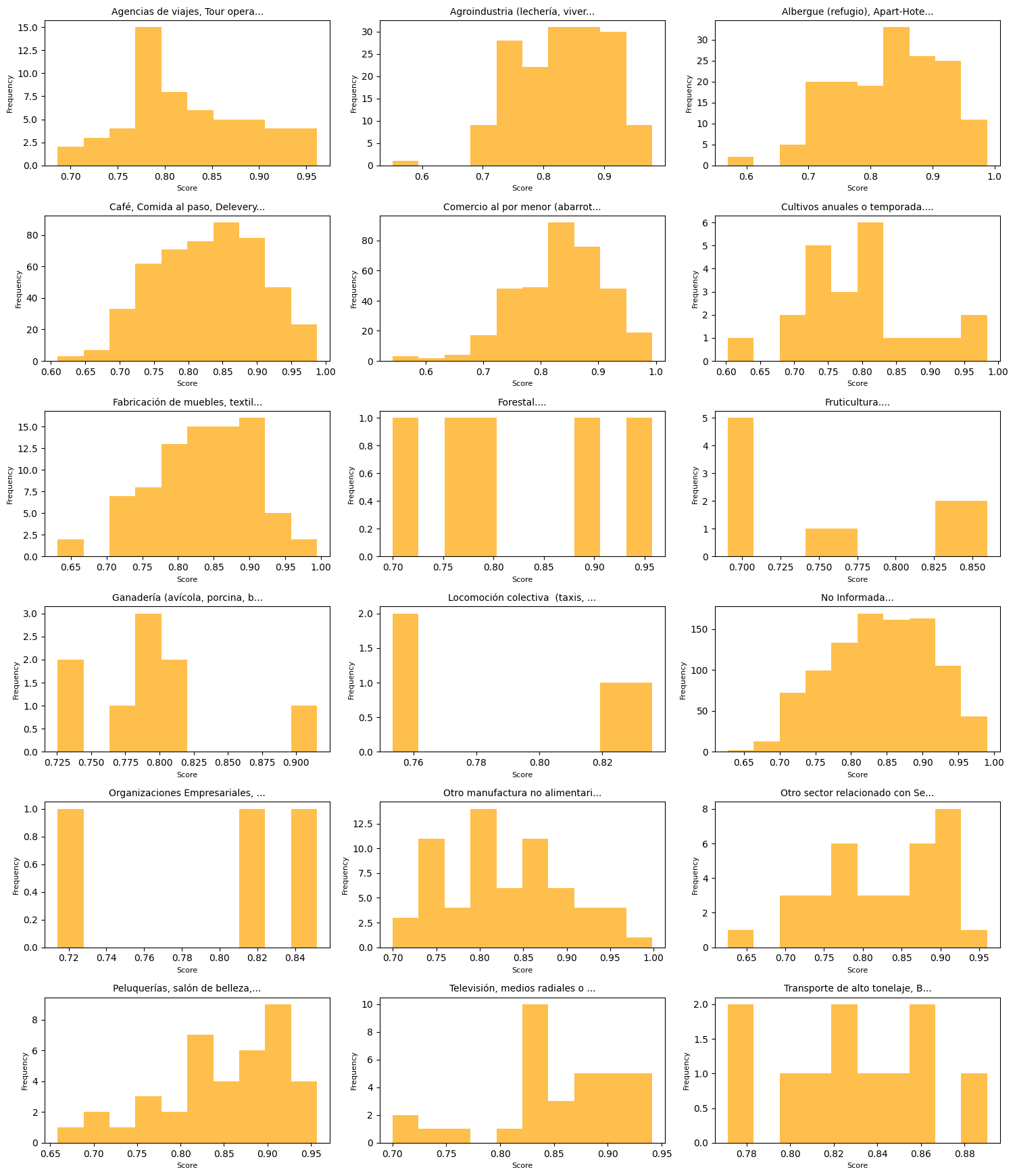
정규화해서 그래도 유효해보이는 결과를 얻었다.
주요 변경 사항
- 유사도 행렬 정규화:
- normalize_similarity_matrix 함수에서 MinMaxScaler를 사용해 유사도 값을 0과 1 사이로 정규화합니다.
- 독창성 점수 계산 함수 수정:
- 유사도 행렬 정규화를 추가하고, 이를 기반으로 독창성 점수를 계산합니다.
2. 메모리 사용량 체크

3. 임베딩 vs 요약 계산량
임베딩(embedding)과 요약(summarization)은 각기 다른 목적과 계산 요구사항이 있으며, 어느 것이 더 계산량이 많고 메모리를 더 많이 사용하는지는 모델의 크기와 사용된 알고리즘에 따라 다릅니다. 하지만 일반적인 차이를 살펴보면 다음과 같습니다:
1. 임베딩 (Embedding)
- 목적: 텍스트를 고정된 크기의 벡터로 변환하여, 검색, 군집화, 분류 등 다양한 작업에서 사용.
- 작업의 성격: 임베딩은 주로 텍스트 입력을 고정 크기 벡터로 변환하는 작업이며, 모델이 특정 차원의 벡터를 생성하는 데 최적화됨.
- 계산량:
- 보통 단순히 입력 텍스트를 벡터로 변환하는 작업만 수행.
- 예: BERT, GPT 등에서 CLS 토큰 벡터 추출.
- 단어 수준이나 문장 수준의 벡터로 추출하는 경우 계산량이 비교적 적음.
- 메모리 요구:
- 메모리는 주로 모델 파라미터와 입력 길이에 따라 결정.
- 결과물은 고정 크기 벡터로 압축되므로, 생성된 데이터의 메모리 사용량은 작음.
2. 요약 (Summarization)
- 목적: 긴 텍스트에서 중요한 정보를 추출하여 짧고 이해하기 쉬운 형태로 변환.
- 작업의 성격: 요약은 텍스트를 생성하는 작업으로, 텍스트 생성 모델(예: GPT 계열)은 입력을 이해하고 적절한 출력 텍스트를 생성하기 위해 더 많은 계산을 요구.
- 계산량:
- 요약은 입력 텍스트를 처리하고, 적절한 출력을 생성하기 위해 디코더 단계에서 더 많은 연산을 수행.
- 입력 길이가 길고 출력 텍스트도 길수록 계산량이 더 커짐.
- 메모리 요구:
- 요약은 입력과 출력 모두를 메모리에 저장해야 하며, 특히 **주의 메커니즘(attention mechanism)**에서 입력 길이에 따라 메모리 사용량이 비례적으로 증가.
- 생성된 텍스트의 길이에 따라 메모리 요구량도 증가.
결론 비교
- 계산량:
- 요약이 일반적으로 더 계산량이 많습니다. 요약은 입력 데이터를 해석하고 새로운 텍스트를 생성하기 때문에 임베딩보다 복잡한 작업입니다.
- 메모리 사용량:
- 요약이 더 많은 메모리를 사용합니다. 특히 긴 입력과 출력이 있을 때 메모리 요구량이 크게 증가합니다.
- 임베딩은 고정된 크기의 벡터만 생성하므로 메모리 사용량이 작습니다.
실질적인 선택
- 효율이 중요: 임베딩을 사용하세요.
- 내용 생성이나 요약: 요약 작업을 사용하되, 긴 입력을 처리할 때 메모리 제한을 고려해야 합니다.
요약은 내용 생성까지 수행하므로 계산량 더 증가
4. groupby 함수
별도 포스트로 정리
5. max_token 2000 돌리고 있는 중이지만 불안하게도 잘 안됨 ㅠㅠ
'proyector en Chile' 카테고리의 다른 글
| 유사도 측정 알고리즘 정교화 방법 (0) | 2025.01.27 |
|---|---|
| Box Plot 해석 (0) | 2025.01.24 |
| [groupby] 특정 열을 기준으로 데이터프레임 그룹화 (0) | 2025.01.22 |
| Big O 표기 (0) | 2025.01.22 |
| 0120_오늘 한 일 (0) | 2025.01.21 |
'proyector en Chile' Related Articles
more

